1Sharding-JDBC 介绍 · SpringCloud微服务实战 · 看云
导航
官网地址:https://shardingsphere.apache.org/index_zh.html,目前已捐献给Apache
1. 数据库分片思想
1.1 垂直切分
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。
1.2 水平切分
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表)
2. Sharding-JDBC 简介
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
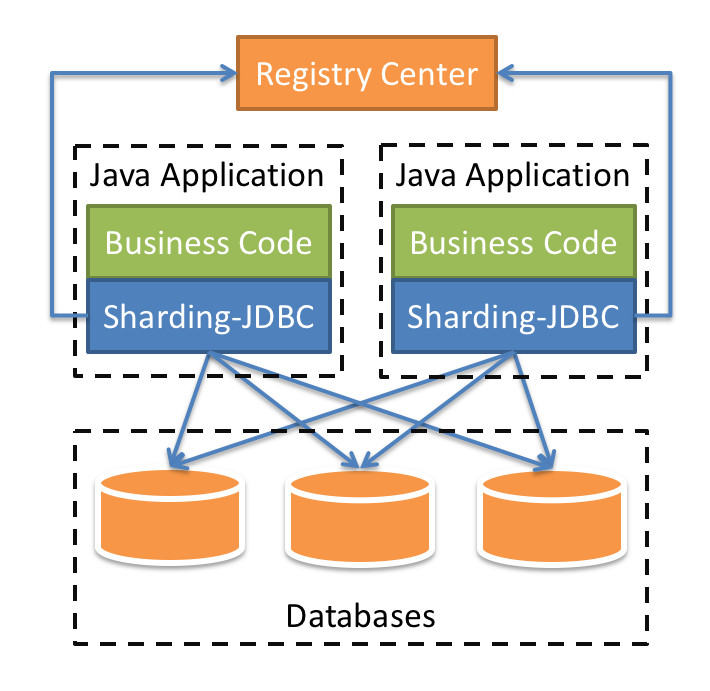
Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;
3. 功能列表
- 分库 & 分表
- 读写分离
- 分布式主键
- 数据脱敏
4. 分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
4.1 精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
4.2 范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
4.3 复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
4.3 Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
5. 分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度。
5.1 数据源分片策略
对应于DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
5.2 表分片策略
对应于TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
两种策略的API完全相同。
6. 广播表、绑定表、逻辑表 、真实表、 数据节点 的区分
首先这些概念先搞清楚,不然容易搞混
- 广播表
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表
- 逻辑表
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是
t_order_0到t_order_9,他们的逻辑表名为t_order
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是
- 真实表
- 在分片的数据库中真实存在的物理表。即上个示例中的
t_order_0到t_order_9
- 在分片的数据库中真实存在的物理表。即上个示例中的
- 数据节点
- 数据分片的最小单元。由数据源名称和数据表组成,例:
ds_0.t_order_0
- 数据分片的最小单元。由数据源名称和数据表组成,例:
- 绑定表
- 指分片规则一致的主表和子表。例如:
t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
- 指分片规则一致的主表和子表。例如:
举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
7. 优缺点
优点:
- 以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动
- 对代码没有侵入
- 性能较高,操作简单
- 文档较全
缺点:
- 会使数据库的连接数增加
8. 内容介绍
本章我们主要讲解Sharding-JDBC的几种常见用法
- 读写分离
- 分库分表
- 分库分表基于java bean的配置
- 分库分表+读写分离
- 同库分表
- 同库分表+读写分离
- 多租户实战